
この記事では文章のような長いテキストから必要な部分を取得するテクニックを紹介するニャ
この方法では、取得したいテキストに特定の文字列が含まれていたり、前後に特定の文字列がある場合など、何かしらの規則性がないと取得できませんので、ご注意ください。
サンプルテキスト
今回ご紹介する例では、以下のサンプルテキストから、部分的にテキストを取得してみたいと思います。
問い合わせフォームから問い合わせが入ると、決まったテンプレートで通知が届くことを想定し、質問者が入力した内容が可変で埋め込まれるような文章です。
問い合わせがありました。
■氏名
山田太郎
■カテゴリ
荷物が届かない
■伝票番号
1234-5678-90
■内容
配達完了のメールが届きましたが、荷物が届いていません。家族の受け取りや配達ボックスも確認済みです。調査をお願いします。
取得方法
それでは氏名を例に取得してみましょう。
部分的にテキストを取得するには、取得したい部分の規則性を判断し、「テキストの解析」アクションと「サブテキストの取得」アクションを組み合わせることでテキストを取得します。
今回の例では、抽出したい氏名は、「■氏名」と「■カテゴリ」のテキストの間にあることが分かります。
どのような名前が可変で入ってきたとしても、この前提は変わらないため、「■氏名」と「■カテゴリ」がテキスト全体の何文字にあるのかが分かれば、その情報から間にあるテキストを取得することができます。
なかなか文章だけでは理解しにくいと思いますので、実際にフローで確認してみましょう。
テキストの解析
まずは「テキストの解析」アクションを使って「■氏名」の出現箇所を調べます。
今回は上記のサンプルテキストが %Sample% という変数に設定されているとします。
%Sample% から「■氏名」の出現箇所を調べるために「テキストの解析」アクションを設定します。

これを実行すると、結果を格納した %PositionName% には「14」が格納されました。
同様に「■カテゴリ」も「テキストの解析」アクションを使って出現箇所を調べると、「23」が格納されました。

つまり「■氏名」はテキスト全体の14番目の位置、「■カテゴリ」は23番目の位置から開始されているということが分かります。

この2つの情報が分かれば、「サブテキストの取得」アクションを使って間にある氏名のテキストを取得することができます。
サブテキストの取得
「サブテキストの取得」でテキストを取得するために必要な情報は、テキストの開始位置と長さです。
取得したい氏名の部分、今回で言うと「山田太郎」というテキストは「■氏名」の位置から+4番目が開始位置になります。(文字数のカウントには改行も含まれます)

「■氏名」から+4番目、つまり %PositionName + 5% が取得したいテキストの開始位置になります。
あと必要な情報はテキストの長さです。
今回で言うと、取得したい「山田太郎」は4文字なので、結果的に「4」という値を設定できればいいのですが、もちろん氏名の長さは3文字になったり、5文字になったり、長さは変わる可能性があります。
ここまでテキストの出現箇所が分かっただけで、テキストの長さについては何も情報が無いですが、ここまで調べた2つの情報を使って、テキストの長さを算出することができます。
まず、テキストの長さは、【テキストの終了の文字位置 – 開始の文字位置】で算出することができます。

開始位置はすでに分かっているので、続いてテキストの終了位置を算出しましょう。
終了位置を算出するにあたって「■カテゴリ」の開始位置はすでに分かっています。この開始位置から-1番目、つまり 変数にすると %Position_Category – 1% が取得したいテキストの終了位置になります。
よって終了位置から開始位置を引くと文字数になるので、文字数の長さは以下のように算出することができます。
%(PositionCategory - 1) - (PositionName + 4)%今回の例では %PositionName% に14、%PositionCategory% に23が設定されていましたので、値を入れて計算してみると、文字数の「4」となることが分かります。
これをアクションに設定すると、以下のようになり、これで部分的にテキストを取得することができました。

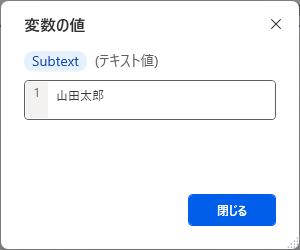
少し難しいですが、規則性のある文章であれば、このようにしてテキストを部分的に取得することができるニャ